I have done a fair bit of reading and experimenting with a concept people call "CQS" or "CQRS". For a good discussion about the possible difference see Greg Young's post. From here on in I am going to assume they are the same thing for simplicity.
I am not going to do an in depth post about why you should or should not use this pattern/concept, I will only provide an overview. I am however going to show you one common application where I have found it brings great benefits using an ASP.NET MVC Web Application which relies heavily on server side caching of data and async controllers.
All the code in this article is on Github and some of the usable components are available in the following NuGet packages:
In case you do not want to research elsewhere, the main reason to use CQS/CQRS is to follow the single responsibility principle. Benefits include more modular, testable code.
The only argument I can find against using CQS/CQRS seems to be that in some cases it might over-complicate the solution. This would in theory make the code less maintainable for a developer who was not familiar the pattern or found it a bit abstract. In my experience, I have never been asked to build a pure CRUD application with no extra bells and whistles, so I struggle to think of an example where this would not be a good idea when data is involved.
One common example to argue CQS/CQRS would not be overkill in a typical web application is the concept of caching. When you cache some data on the server side, you have now introduced a second data source alongside your primary database. At this point, unless you are only doing really simple caching, cache management can become very complicated and error-prone. When you add something to cache, you need to also manage when to remove or update it.
Along with caching to improve speed, one performance improvement concept to ensure a more scalable web application is asynchronous server side processing. I recommend doing your own reading on this topic, but in a nut shell: in an ASP.NET web application (MVC or Web Forms) there are a limited number of "worker" threads able to process requests. If all of them are in use requests start to queue up and eventually fail if the server cannot handle the load (search for "Asynchronous Pages" if using WebForms, or "Asynchronous Controllers" if using MVC to learn more).
When you combine caching and async, it is very easy to implement a poor design. As a general rule: if you are retrieving data from a database or external data source it should be done on a background thread, and if you are retrieving from a local cache it should use the worker thread. As you can imagine when this kind of logic is littered throughout your code, in combination with already complicated cache management code, it can become a real mess very quickly.
Time for some code. In a sample app, assume we have a collection of "Thingy's" where a "Thingy" has an ID and a Name. You can add and edit Thingy's. The collection of all Thingys is cached when you get to the screen that lists them. Each individual Thingy is cached when you view it's detail. This is a poor example of a real world application as you would probably not cache the individual items, but for demonstration purposes it allows me to show how this pattern makes cache management cleaner.
Here is the "ThingysController" that retrieves all the data to display for the list:
 (https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/Controllers/ThingysController.cs)
(https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/Controllers/ThingysController.cs)
You will notice the controller action "Index" is marked with the keyword "async". This does not mean it will always run asynchronously, it will only spawn a new thread if it needs to. If the code takes "Path A" (I.e. the data was retrieved from cache), then it will all happen on one thread. If the code however takes "Path B", then the "ExecuteAsync" method will be processed on a background thread, and a new thread will resume processing the request when it is finished. All the complexity of caching is implemented in the IGetAllThingysQuery implementation and as we will see later some other components.
Here is the code for the Query itself that is allowing this controller code to be so simple:
 (https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/Query/GetAllThingysQuery.cs)
(https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/Query/GetAllThingysQuery.cs)
This query has the "single repsonsibility" of "retrieving all Thingys". Sometimes that is from cache, sometimes it is from the database. You may notice there is a method "missing" - "ExecuteAsync" which the controller is calling. That is created in the "QueryBase" class which just wraps the "Execute" method in a task so it can be called using the "await" keyword. The other thing to note is the event publisher. This class does not have to worry about how to cache the items, it just raises an event and some other object can deal with that. The other object in this case is the "ThingysRetrievedEventSubscriber":
 (https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/EventSubscriber/ThingysRetrievedEventSubscriber.cs)
(https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/EventSubscriber/ThingysRetrievedEventSubscriber.cs)
The code for "ThingyController" to show one selected Thingy and it's underlying Query and events are very similar so I will leave them out of this post but it is important to note they are both writing to different cache keys when their data is accessed.
Now for updating data. Here is the ThingyController method that accepts a POST to update data:
 (https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/Controllers/ThingyController.cs)
(https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/Controllers/ThingyController.cs)
As you can see, the validation is done on the worker thread, however the command to update the data will run on a background thread as demonstrated in the "await" line.
Now, the code for the SaveThingyCommand:
 (https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/Command/SaveThingyCommand.cs)
(https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/Command/SaveThingyCommand.cs)
The command has the responsibility of saving data if it needs to be saved. It keeps track of what happened so that when it publishes an event, the event subscriber(s) can be clever about how they handle what happened. In this example, if someone saves a Thingy, but they actually did not change anything, then it would be inefficient to clear the cache because nothing has happened. So the "action" in this event is just a concept I came up with, not every command will track this kind of information.
Here is the handler of the event published, which closes the loop on how the cached items are removed when a change is made (I.e. the individual item that was updated is removed from cache, but it also clears the full list of the cached items from the "GetAllThingys" query to be safe):
 (https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/EventSubscriber/ThingyChangedEventSubscriber.cs)
(https://github.com/nootn/DotNetAppStarterKit/blob/master/DotNetAppStarterKit.SampleMvc/DataProject/EventSubscriber/ThingyChangedEventSubscriber.cs)
You could argue that this event subscriber should be split in two - one that handles removing the individual item and one that handles removing the collection of all items. That would be fine and very simple to implement. It depends on what you feel the responsibility of this subscriber should be. In this case I chose to combine since it's such a simple example.
It is pertinent to mention that the EventSubscribers in DotNetAppStarterKit will be run on the same thread as the code that published the event. There is no extra threading added. If your event subscriber should run on a separate thread that would be simple to implement. I think this pattern also extends nicely into more complicated scenarios where your event publisher might be a message bus of some kind where the web application fires and forgets, rather than all the code needing to be within the web application.
If you struggle to follow the blog post I understand as it's very difficult to explain how this works in writing. I would recommend grabbing a copy of DotNetAppStarterKit source code and running up the SampleMvc web application. There is some tracing in there that explains what is going on, or just put some breakpoints in the code and check out what is happening at each stage.
I look forward to hearing comments from people on whether they think this is a good approach or if it has some flaws! Hopefully if you like it the DotNetAppStarterKit NuGet packages will save you some valuable time.
I am not going to do an in depth post about why you should or should not use this pattern/concept, I will only provide an overview. I am however going to show you one common application where I have found it brings great benefits using an ASP.NET MVC Web Application which relies heavily on server side caching of data and async controllers.
All the code in this article is on Github and some of the usable components are available in the following NuGet packages:
In case you do not want to research elsewhere, the main reason to use CQS/CQRS is to follow the single responsibility principle. Benefits include more modular, testable code.
The only argument I can find against using CQS/CQRS seems to be that in some cases it might over-complicate the solution. This would in theory make the code less maintainable for a developer who was not familiar the pattern or found it a bit abstract. In my experience, I have never been asked to build a pure CRUD application with no extra bells and whistles, so I struggle to think of an example where this would not be a good idea when data is involved.
One common example to argue CQS/CQRS would not be overkill in a typical web application is the concept of caching. When you cache some data on the server side, you have now introduced a second data source alongside your primary database. At this point, unless you are only doing really simple caching, cache management can become very complicated and error-prone. When you add something to cache, you need to also manage when to remove or update it.
Along with caching to improve speed, one performance improvement concept to ensure a more scalable web application is asynchronous server side processing. I recommend doing your own reading on this topic, but in a nut shell: in an ASP.NET web application (MVC or Web Forms) there are a limited number of "worker" threads able to process requests. If all of them are in use requests start to queue up and eventually fail if the server cannot handle the load (search for "Asynchronous Pages" if using WebForms, or "Asynchronous Controllers" if using MVC to learn more).
When you combine caching and async, it is very easy to implement a poor design. As a general rule: if you are retrieving data from a database or external data source it should be done on a background thread, and if you are retrieving from a local cache it should use the worker thread. As you can imagine when this kind of logic is littered throughout your code, in combination with already complicated cache management code, it can become a real mess very quickly.
Time for some code. In a sample app, assume we have a collection of "Thingy's" where a "Thingy" has an ID and a Name. You can add and edit Thingy's. The collection of all Thingys is cached when you get to the screen that lists them. Each individual Thingy is cached when you view it's detail. This is a poor example of a real world application as you would probably not cache the individual items, but for demonstration purposes it allows me to show how this pattern makes cache management cleaner.
Here is the "ThingysController" that retrieves all the data to display for the list:

You will notice the controller action "Index" is marked with the keyword "async". This does not mean it will always run asynchronously, it will only spawn a new thread if it needs to. If the code takes "Path A" (I.e. the data was retrieved from cache), then it will all happen on one thread. If the code however takes "Path B", then the "ExecuteAsync" method will be processed on a background thread, and a new thread will resume processing the request when it is finished. All the complexity of caching is implemented in the IGetAllThingysQuery implementation and as we will see later some other components.
Here is the code for the Query itself that is allowing this controller code to be so simple:

This query has the "single repsonsibility" of "retrieving all Thingys". Sometimes that is from cache, sometimes it is from the database. You may notice there is a method "missing" - "ExecuteAsync" which the controller is calling. That is created in the "QueryBase" class which just wraps the "Execute" method in a task so it can be called using the "await" keyword. The other thing to note is the event publisher. This class does not have to worry about how to cache the items, it just raises an event and some other object can deal with that. The other object in this case is the "ThingysRetrievedEventSubscriber":
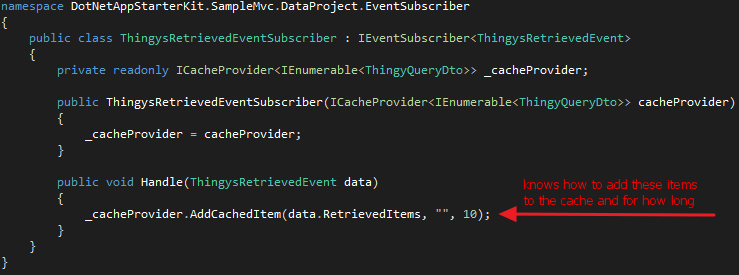
The code for "ThingyController" to show one selected Thingy and it's underlying Query and events are very similar so I will leave them out of this post but it is important to note they are both writing to different cache keys when their data is accessed.
Now for updating data. Here is the ThingyController method that accepts a POST to update data:

As you can see, the validation is done on the worker thread, however the command to update the data will run on a background thread as demonstrated in the "await" line.
Now, the code for the SaveThingyCommand:

The command has the responsibility of saving data if it needs to be saved. It keeps track of what happened so that when it publishes an event, the event subscriber(s) can be clever about how they handle what happened. In this example, if someone saves a Thingy, but they actually did not change anything, then it would be inefficient to clear the cache because nothing has happened. So the "action" in this event is just a concept I came up with, not every command will track this kind of information.
Here is the handler of the event published, which closes the loop on how the cached items are removed when a change is made (I.e. the individual item that was updated is removed from cache, but it also clears the full list of the cached items from the "GetAllThingys" query to be safe):

You could argue that this event subscriber should be split in two - one that handles removing the individual item and one that handles removing the collection of all items. That would be fine and very simple to implement. It depends on what you feel the responsibility of this subscriber should be. In this case I chose to combine since it's such a simple example.
It is pertinent to mention that the EventSubscribers in DotNetAppStarterKit will be run on the same thread as the code that published the event. There is no extra threading added. If your event subscriber should run on a separate thread that would be simple to implement. I think this pattern also extends nicely into more complicated scenarios where your event publisher might be a message bus of some kind where the web application fires and forgets, rather than all the code needing to be within the web application.
If you struggle to follow the blog post I understand as it's very difficult to explain how this works in writing. I would recommend grabbing a copy of DotNetAppStarterKit source code and running up the SampleMvc web application. There is some tracing in there that explains what is going on, or just put some breakpoints in the code and check out what is happening at each stage.
I look forward to hearing comments from people on whether they think this is a good approach or if it has some flaws! Hopefully if you like it the DotNetAppStarterKit NuGet packages will save you some valuable time.
Comments
Post a Comment